O Swoole é um framework de programação assíncrona para PHP e já se posiciona como uma opção estável e confiável para se desenvolver de forma concorrente com alta performance e uso equilibrado de recursos. Ele implementa I/O assíncrono orientado a eventos baseado no padrão Reactor (o mesmo utilizado por ReactPHP, NodeJS, Netty do Java, Twisted do Python entre outros). O Swoole é escrito em C e disponibilizado como uma extensão para PHP.
O Swoole permite que escrevamos aplicações altamente performáticas e concorrentes usando TCP, UDP, Unix Socket, HTTP e WebSockets sem que precisemos ter grandes conhecimentos de baixo nível sobre assincronismo e/ou sobre o kernel do Linux. Ele fornece uma completa API de alto nível com foco na produtividade. O Swoole é usado em grandes projetos enterprises, principalmente na China sendo Baidu (maior portal de busca da China) e Tencent (um dos maiores portais de serviços da China) os principais casos de uso.
É muito importante e recomendado que antes de continuar aqui, você leia o artigo sobre Introdução à programação assíncrona em PHP usando o ReactPHP, pois ele vai te introduzir alguns importantes conceitos de como é o modelo tradicional síncrono de se desenvolver em PHP e como funciona o modelo assíncrono usando o padrão Reactor.
Curso PHP Avançado
Conhecer o cursoPara o que veio e para o que não veio o Swoole
O Swoole não veio para substituir a abordagem tradicional e síncrona de como a maioria do projetos em PHP são escritos. Ao contrário disso, ele veio pra suprir os outros casos de uso como, por exemplo, a criação de servidores TCP, RPC, Websockets etc. Ele veio para resolver o problema de servidores que precisem de alta concorrência. Para se ter ideia, um único servidor escrito usando o Swoole consegue lidar com 1 milhão de conexões (C1000K). Também podemos dizer que o Swoole veio para que você não precise mudar toda sua stack e linguagem para resolver as necessidades acima listadas.
Muitas formas de se atingir assincronismo
Síncrono ou assíncrono é sobre o fluxo de execução. É possível atingir assincronismo de diversas formas como, por exemplo, uma fila de mensagens (Amazon SQS, Redis etc) onde você a alimenta com as tarefas (jobs) e no seu servidor você tem uma determinada quantidade de worker processes consumindo essa fila e executando as tarefas de forma concorrente e/ou paralela (a depender dos núcleos da CPU).
Também é possível atingir assincronismo com Ajax, lembra de requisição assíncrona onde é possível enviar a requisição e não ficar esperando pela resposta para poder fazer outra? Também é possível criando novos processos (uma opção mais pesada) ou criando novas threads (mais leve que processos, mas ainda assim, não tão leve quanto corrotinas que veremos adiante). Todas essas coisas podem ser trabalhadas para se chegar no objetivo de atingir assincronismo.
No entanto, o modelo assíncrono do Swoole é focado em nonblocking I/O e I/O multiplexing que é mais popularmente conhecido como event driven (com eventos de leitura e escrita a partir do monitoramento de descritores de arquivos) e usa chamadas de sistema como select, pool ou epool. Além disso, o Swoole implementa corrotinas com o modelo CSP (Communicating sequential processes) que é bem conhecido na linguagem Go com go, chan e defer. Se você já trabalhou com concorrência em Go, terá muita facilidade para assimilar em como as coisas são feitas no Swoole.
A arquitetura tradicional com PHP-FPM
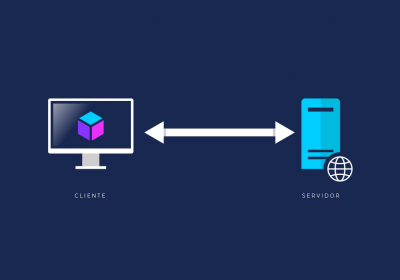
Na arquitetura tradicional da maior parte das aplicações escritas em PHP, temos um servidor web e um process manager baseado no protocolo FastCGI, que no caso do PHP o oficial é o PHP-FPM. No lado do servidor web, o mais usado atualmente é o Nginx, que por sinal, também usa o padrão Reactor com I/O multiplexing (epool) para conseguir responder a milhares de conexões simultâneas, diferentemente do Apache (outro popular servidor) que implementa um modelo híbrido multi-process e multi-thread (quando usando Worker MPM em detrimento ao Prefork MPM).
É relativamente comum ler que o PHP-FPM é multi-thread, mas na realidade ele é multi-process. As requisições são iniciadas pelo servidor web (Nginx, por exemplo) que as redireciona para o PHP-FPM via o protocolo binário FastCGI. O Master Process do PHP-FPM recebe essas requisições e as aloca em um novo worker process. O PHP-FPM gerencia pools de worker processes, cada pool pode gerenciar um determinado número de processos filhos (worker processes) para lidar com as requisições (e esse número depende das configurações do PHP-FPM e da quantidade de memória disponível). Todo esse processo é bloqueante por natureza, ou seja, enquanto o script estiver sendo executado (acessando I/O, por exemplo). Só no final quando a resposta é processada e retornada que o processo filho criado pelo PHP-FPM é reciclado.
Uma nota sobre pools: A ideia de uma pool é pré-alocar uma determinada quantidade de processos ou threads (no caso de uma Thread Pool) para que fiquem em espera para realizarem alguma tarefa em um tempo futuro. É uma forma de evitar desperdício de tempo com a alocação de um novo processo ou thread, que não é uma operação muito leve no nível do kernel. Além disso, é uma forma de determinar recursos finitos para o número de clientes que se espera ter. Por exemplo, se o servidor tem 8GB de memória, mas só podemos usar 6GB para as pools que receberão as requisições, então as configuramos para consumirem no máximo isso, o que vai limitar o número de processos / threads que elas poderão pré-alocar.
Em um cenário onde há necessidade de alta concorrência para responder à milhares ou dezenas de milhares de conexões, todo esse processo tradicional é muito custoso (gasta-se muito tempo com troca de contexto), muita alocação de memória e a concorrência fica limitada à quantidade de processos que sua máquina consegue manejar. Não obstante, é lento, pois a cada nova requisição todo o código precisa ser inicializado do zero novamente. Mas esse modelo tradicional também tem seus benefícios, a depender do ponto de vista. Por exemplo, é um modelo stateless, o tempo de vida de uma requisição é curto, assim que o resultado é preparado e retornado, tudo é finalizado e retirado da memória, isso diminui as chances de memory leaks.
Abaixo o diagrama de como funciona essa arquitetura tradicional. O Nginx recebe as requisições da Web (normalmente advindas das portas 80 e 443) e então as encaminha para o socket FastCGI do PHP-FPM que maneja as execuções nas pools de worker processes.

O fluxo tradicional com PHP-FPM é mais ou menos assim:
- Recebe a requisição;
- Carrega os códigos (processo léxico, de parser, compilação para opcodes etc);
- Inicializa os objetos e variáveis;
- Executa o código;
- Retorna a resposta;
- Recicla os recursos, liberando o worker process para outra requisição;
Para a maioria das aplicações de uso menos intensivo de I/O, esse modelo é perfeito e estável. Mas quando precisamos de um uso mais intensivo como, por exemplo, para lidar com milhares ou centenas de milhares de conexões simultâneas, é impossível que tenhamos centenas de milhares de processos sendo criados para cuidar dessas requisições. Muito menos poderíamos criar centenas de milhares de threads, dada a limitação do número de threads por processo imposta pelo sistema operacional e também devido ao overhead que isso causaria. Mesmo que fosse possível resolver o problema usando um número menor de threads, trabalhar com threads não é simples, impõe muitos problemas de comunicação e sincronia para lidar.
É nesse ponto que entram as soluções de I/O não bloqueante com multiplexing de I/O. É aqui que ReactPHP, Nginx, NodeJS, Netty, Swoole, Go etc, resolvem o problema, cada um na sua maneira. Mas a forma mais comum e mais utilizada é usando uma abordagem orientada a eventos com o padrão Reactor.
O ciclo de vida de uma requisição em um servidor do Swoole se limita a bem menos etapas, pois depois do first load, ele mantém os recursos em memória:
- Recebe a requisição;
- Executa o código;
- Retorna a resposta;
A arquitetura com Swoole
Em um cenário de alta concorrência e em um modelo de I/O não bloqueante como é o caso do Swoole, ele deixa de lidar apenas com uma requisição bloqueante (como funciona no PHP-FPM) e ganha o poder de lidar com várias requisições ao mesmo tempo, de forma não bloqueante, graças aos reactors.
O Swoole roda em modo CLI e ele forka um determinado número de processos a depender da quantidade de núcleos da sua CPU. Veja um panorama da arquitetura do Swoole:

O padrão Reactor no Swoole é multi-thread e assíncrono, igual comentamos anteriormente, ele faz uso da chamada de sistema epool. O Main Reactor é uma thread, assim como os reactors auxiliares. O Main Reactor é o que fica ouvindo o socket por novas conexões, ele faz balanceamento de carga entre os reactors auxiliares.
-
Master: o processo principal, o processo pai, o que forkará o processo Manager e que criará as threads do Reactor.
-
Manager: processo gerenciador, o que forka e gerencia os processos workers. Os reactors estarão em constante comunicação com o Manager (através do processo Master).
-
Worker: processo de trabalho, onde as tarefas são executadas;
-
Task Worker: processo de trabalho de tarefa assíncrona, é um auxiliador do Worker, ele trabalha principalmente processando tarefas de sincronização de longa data;
O mais importante aqui é entendermos que quando iniciamos um servidor do Swoole, 2 + n + m processos são criados, ou seja, o processo Master, o processo Manager e n refere-se aos processos Workers e m refere-se aos processos Task Workers, sendo que n e m serão relativos à quantidade de núcleos do seu processador. Se o seu processador tiver 6 núcleos, ele forkará 8 processos, sendo 3 Workers e 3 Task Workers.
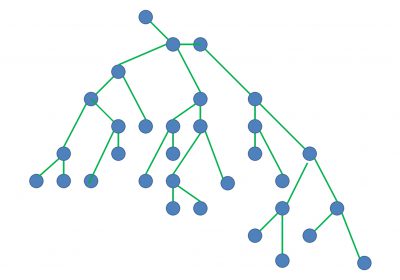
A árvore de processo da execução de um servidor do Swoole em uma máquina de 6 núcleos:
| | \-+= 05535 kennedytedesco php server.php (Master)
| | \-+- 05536 kennedytedesco php server.php (Manager)
| | |--- 05537 kennedytedesco php server.php (worker / task worker)
| | |--- 05538 kennedytedesco php server.php (worker / task worker)
| | |--- 05539 kennedytedesco php server.php (worker / task worker)
| | |--- 05540 kennedytedesco php server.php (worker / task worker)
| | |--- 05541 kennedytedesco php server.php (worker / task worker)
| | \--- 05542 kennedytedesco php server.php (worker / task worker)
Quando trabalhamos de forma assíncrona não sabemos em qual tempo futuro a nossa resposta estará pronta e então passamos a usar os famosos callbacks. Com o tempo, é comum termos muitos callbacks aninhados, é aí que chegamos no famoso Callback Hell. Por exemplo, em NodeJS:
fs.readdir(source, function (err, files) {
if (err) {
console.log('Error finding files: ' + err)
} else {
files.forEach(function (filename, fileIndex) {
console.log(filename)
gm(source + filename).size(function (err, values) {
if (err) {
console.log('Error identifying file size: ' + err)
} else {
console.log(filename + ' : ' + values)
aspect = (values.width / values.height)
widths.forEach(function (width, widthIndex) {
height = Math.round(width / aspect)
console.log('resizing ' + filename + 'to ' + height + 'x' + height)
this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) {
if (err) console.log('Error writing file: ' + err)
})
}.bind(this))
}
})
})
}
})
Existem várias formas que diferentes linguagens/frameworks usam para resolver esse problema, como: Promises (recomendo a leitura do artigo de Promises no ReactPHP) , yield/generators, instruções Async / Await (como em C#).
Em Swoole a forma mais elegante e eficiente de resolver esse problema é usando corrotinas. Corrotinas são uma importante parte do núcleo do Swoole.
Um pouco da sintaxe de corrotinas:
<?php
use Swoole\Coroutine\System;
go(static function () {
System::sleep(1);
echo 'a';
});
go(static function () {
System::sleep(2);
echo 'b';
});
Corrotina (Coroutine)
Programação concorrente é a composição de atividades independentes e o modelo tradicional de se aplicar concorrência é o multi threaded com memória compartilhada. Mas existem muitos desafios nas trocas mensagens, sincronização, sem contar que todas essas operações são custosas a nível de consumo de recursos. E se existisse uma forma mais simples e bem mais leve de se ter concorrência? Sim, existe! As corrotinas se propõem a resolver esse problema.
O uso de concorrência para “ocultar” a latência das operações I/O se faz cada vez mais necessário com aplicativos que necessitam servir dezenas ou centenas de milhares de clientes simultaneamente. Corrotinas são uma forma de se aplicar concorrência, onde valores são passados entre atividades independentes (coroutines). Já os canais (channels) são o mecanismo que uma corrotina tem para se comunicar com outra corrotina (passando valores).
Há o senso de que corrotinas são uma espécie de “threads de peso leve”. Alguns autores chamam corrotinas de “green threads”, pra dar essa ideia de que são leves, consomem menos recursos. Mas isso não pode ser levado no sentido literal, pois corrotinas não são threads. Todas as operações de uma corrotina acontecem no modo do usuário (user mode), não envolve diretamente o kernel (kernel mode) como acontece com as threads, isso faz com que o custo de criação e consumo de recursos aconteça em uma escala muito menor. O paralelo de se comparar corrotinas com threads é útil apenas para que entendamos quando devemos utilizá-las. Basicamente todo caso de uso que teríamos com threads, podemos fazer com corrotinas. O Swoole por padrão cria uma corrotina para cada requisição recebida, esse que também é o padrão em Go. Teremos um artigo focado só em corrotinas.
Desde a versão 4 o Swoole provê um completo suporte à corrotinas, num modelo relativamente parecido com o que se implementa em Go, mas com algumas diferenças internas fundamentais, pois no Swoole uma única corrotina é executada por vez através de um scheduler single threaded. Enquanto em Go o scheduler de corrotinas é multi threaded, ele paraleliza a execução das corrotinas (e internamente usa locks e mutex para controlar a sincronização).
Nota: Scheduling é um mecanismo que atribui tarefas para serem executadas nos workers, é o mecanismo que gerencia qual tarefa será executada em um dado momento, e quem aplica esse mecanismo é o scheduler. Num modelo mais tradicional, pensando no scheduler de um sistema operacional, tarefa seria uma thread e worker seria um núcleo da CPU. No caso do Swoole, tarefa é uma corrotina e worker é um worker process.
Ambos os modelos tem seus prós e contras. O “contra” do modelo do Swoole é que para compartilhar variáveis globais e recursos entre diferentes processos do Swoole, precisa-se pensar um pouco mais, se vai usar IPC (Inter Process Communication) ou outra abordagem (Table, Atomic etc). Mas esse costuma ser um caso de uso bem mais específico. Na maior parte dos casos o desenvolvedor não precisará ter esse tipo de preocupação.
O pró do modelo do Swoole é que para atualizar recursos compartilhados entre corrotinas, não precisamos nos preocupar em implementar locks (pra cuidar do acesso concorrente a um mesmo recurso), uma vez que a execução é single-thread e que as corrotinas são executadas uma por vez. O fato de de o scheduler de corrotinas operar em uma única thread pode dar uma sensação de que ele não é tão eficiente, mas é importante ressaltar que as corrotinas são pausadas/resumidas a partir de eventos de I/O, então a alternância de execução delas pelo scheduler ocorre de maneira muito alta, não dando muito tempo para ociosidade.
Falando sobre custos e as dificuldades de cada abordagem, temos esse comparativo:
| Multi-processo | Multi-thread | Corrotinas | |
|---|---|---|---|
| Criação | Chamada de sistema fork() |
Pthreads API pthread_create() |
Função go() |
| Custo de Scheduling | Alto | Moderado | Extremamente baixo |
| Concorrência | Centenas de processos | Milhares de threads | Centenas de milhares de corrotinas |
| Dificuldade de desenvolvimento | Alta | Muito alta | Baixa |
Executando os primeiros exemplos
O melhor recurso para visualizar alguns exemplos do que é possível fazer com o Swoole é o Swoole by Examples. Clone esse repositório na sua máquina e então execute o comando abaixo para inicializar os containers:
Observação: É necessário que você tenha Docker instalado na sua máquina.
Curso Spring Framework - Trabalhando com testes automatizados
Conhecer o curso$ docker-compose up -d
O primeiro exemplo que vamos executar trata-se de uma execução síncrona (tradicional):
<?php
(function () {
sleep(2);
echo "1";
})();
(function () {
sleep(1);
echo "2";
})();
Execute no terminal:
$ docker-compose exec client bash -c "time ./io/blocking-io.php"
O resultado será:
12
real 0m3.029s
user 0m0.010s
sys 0m0.010s
O script levou cerca de 3 segundos pra executar e retornou 12. A função sleep() foi usada para simular um bloqueio de I/O.
O mesmo exemplo escrito de forma assíncrona usando corrotinas:
<?php
go(function () {
co::sleep(2);
echo "1";
});
go(function () {
co::sleep(1);
echo "2";
});
Execute:
$ docker-compose exec client bash -c "time ./io/non-blocking-io.php"
O resultado será:
21
real 0m2.033s
user 0m0.020s
sys 0m0.000s
Executou em cerca de dois segundos, ou seja, ele custou o tempo da maior execução para retornar os resultados, ao invés de executar cada uma função de forma bloqueante, o que custaria 3 segundos.
Benchmarking
Usando a ferramenta wrk gerei benchmarking de quatro servidores “hello world” rodando em diferentes plataformas:
1) Servidor embutido do PHP;
2) Servidor em NodeJS;
3) Servidor em Go;
4) Servidor Swoole;
O exemplo do servidor embutido do PHP:
<?php
// vanilla.php
echo "Hello World";
Iniciei o servidor embutido:
$ php -S 127.0.0.1:8101 vanilla.php
E então rodei o benchmarking:
$ wrk -t4 -c200 -d10s http://127.0.0.1:8101
O resultado foi:
Running 10s test @ http://127.0.0.1:8101
4 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.46ms 9.56ms 141.27ms 98.92%
Req/Sec 1.41k 1.70k 9.47k 85.45%
8871 requests in 10.05s, 1.47MB read
Socket errors: connect 0, read 9275, write 0, timeout 0
Requests/sec: 882.46
Transfer/sec: 149.95KB
Conseguimos 882 requisições por segundo.
No servidor escrito em NodeJS:
const http = require('http');
const server = http.createServer((req, res) => {
res.end('Hello World')
});
server.listen(8101, '0.0.0.0');
O resultado foi:
Running 10s test @ http://127.0.0.1:8101
4 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 4.05ms 1.09ms 43.57ms 98.31%
Req/Sec 12.49k 1.46k 13.49k 97.03%
502227 requests in 10.10s, 53.16MB read
Socket errors: connect 0, read 110, write 0, timeout 0
Requests/sec: 49720.54
Transfer/sec: 5.26MB
Consegui cerca de 50 mil requisições por segundo.
No servidor escrito em Go:
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", HelloServer)
_ = http.ListenAndServe(":8101", nil)
}
func HelloServer(w http.ResponseWriter, r *http.Request) {
_, _ = fmt.Fprintf(w, "Hello World")
}
O resultado foi:
Running 10s test @ http://127.0.0.1:8101
4 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.05ms 624.03us 42.09ms 92.46%
Req/Sec 47.05k 2.31k 50.59k 95.50%
1873010 requests in 10.00s, 228.64MB read
Socket errors: connect 0, read 48, write 0, timeout 0
Requests/sec: 187280.40
Transfer/sec: 22.86MB
Cerca de 188 mil requisições por segundo.
Agora, no servidor do Swoole:
<?php
use Swoole\Http\Server;
use Swoole\Http\Request;
use Swoole\Http\Response;
$server = new Server('0.0.0.0', 8101);
$server->on('request', static function (Request $request, Response $response) {
$response->header('Content-Type', 'text/plain');
$response->end('Hello World');
});
$server->start();
O resultado foi:
Running 10s test @ http://127.0.0.1:8101
4 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 0.87ms 660.42us 42.95ms 98.60%
Req/Sec 48.55k 3.12k 53.67k 88.75%
1933132 requests in 10.01s, 304.19MB read
Socket errors: connect 0, read 41, write 0, timeout 0
Requests/sec: 193149.91
Transfer/sec: 30.39MB
Não, você não está vendo errado, foram 193 mil requisições por segundo, um pouco mais do que conseguimos com Go. É um número impressionante.
Esse tipo de benchmarking com exemplos simples e hipotéticos não possuem um valor tão significativo, eles precisam ser relativizados, pois as coisas mudam em uma aplicação real que faz um uso mais intensivo de I/O. Ainda assim, é possível enxergar um espectro do que a tecnologia pode alcançar e também nos ajuda a fazer comparações com outras plataformas, como fizemos com NodeJS e Go.
Considerações finais
Esse artigo teve como objetivo fazer um comparativo entre o modelo tradicional síncrono com o assíncrono não bloqueante orientado a eventos. Também foram passadas as principais ideias por trás do Swoole.
Por fim, é interessante informar que o Swoole permite em sua API que implementemos outros padrões como Thread pool pattern. O Swoole também permite que criemos aplicações multi-process.
Leitura sugerida
Dando continuidade aos estudos de Swoole, sugiro a leitura do artigo sequência: Trabalhando com corrotinas, canais e explorando um pouco mais o scheduler de corrotinas do Swoole